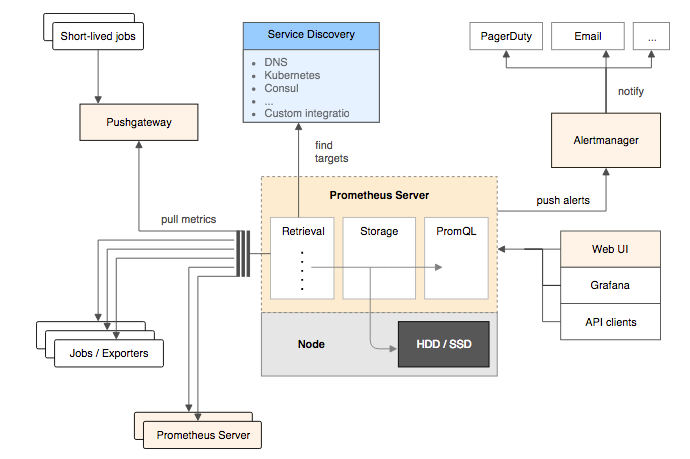
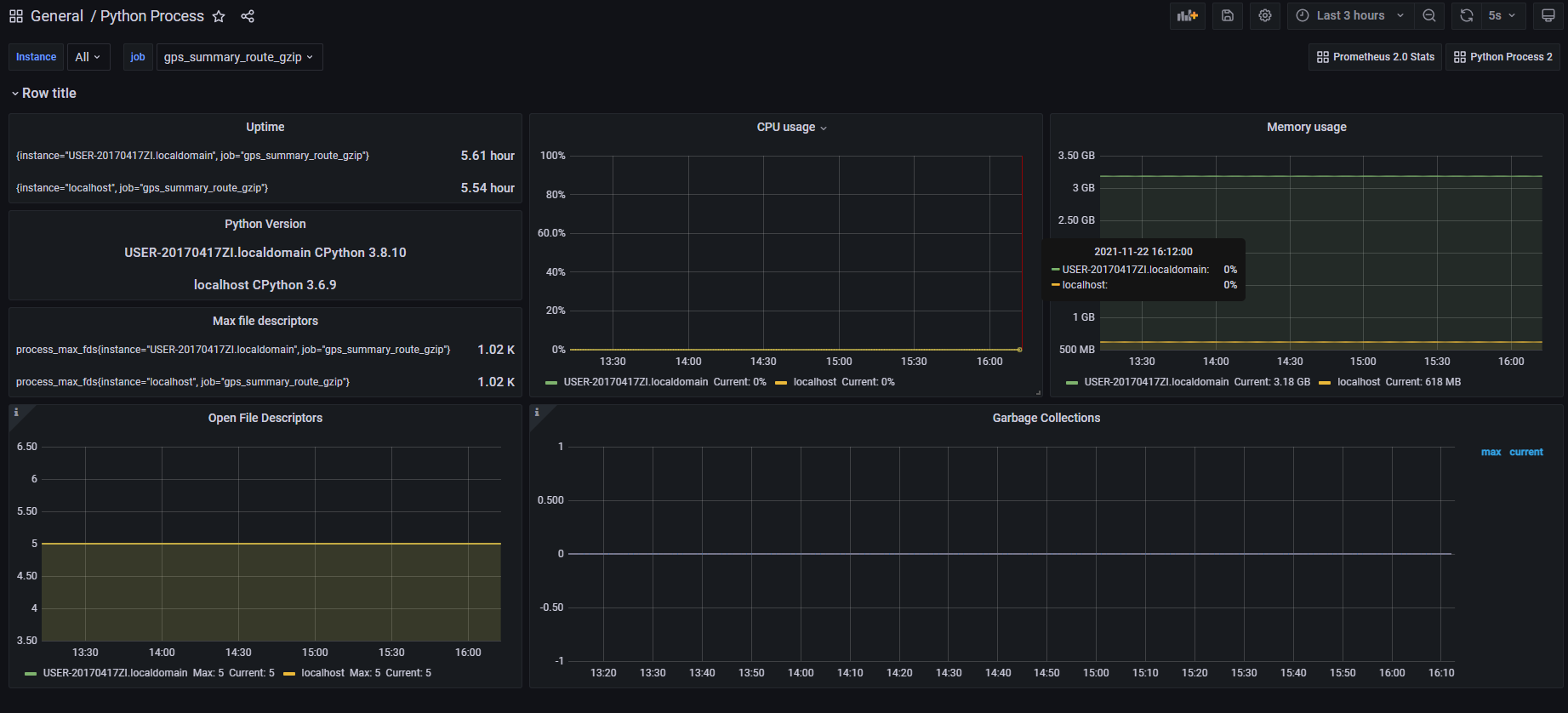
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
| import socket
import threading
import time
from prometheus_client import (
push_to_gateway,
registry,
)
def monitor(gateway: str, job: str, interval: int):
while True:
push_to_gateway(
gateway=gateway,
job=job,
registry=registry.REGISTRY,
grouping_key={"instance": socket.getfqdn()},
)
time.sleep(interval)
def start_monitor(gateway: str, job: str, interval: int = 10):
"""启动监控
:param gateway: 网关地址
:param job: 任务名
:param interval: 统计频率
"""
t = threading.Thread(target=monitor, args=(gateway, job, interval))
t.daemon = True
t.start()
if __name__ == "__main__":
start_monitor('127.0.0.1:9091', job='test_mem', interval=10)
l = []*100000
while True:
time.sleep(1)
l.extend([]*100000)
|