1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
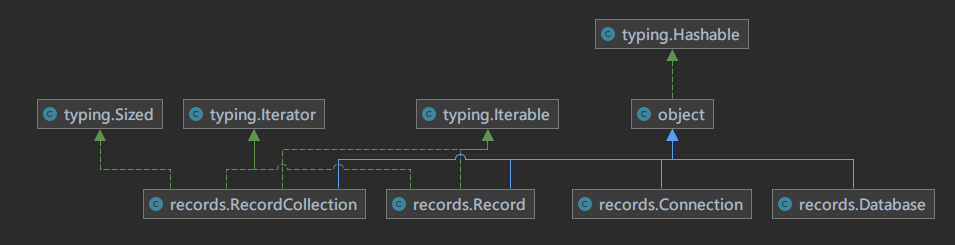
| class RecordCollection(object):
""" Record 记录集合 """
def __init__(self, rows):
self._rows = rows
self._all_rows = []
self.pending = True
def __iter__(self):
"""迭代器方法 大量数据时提升性能,节省内存 """
i = 0
while True:
if i < len(self):
yield self[i]
else:
try:
yield next(self)
except StopIteration:
return
i += 1
def __next__(self):
try:
nextrow = next(self._rows)
self._all_rows.append(nextrow)
return nextrow
except StopIteration:
self.pending = False
raise StopIteration('RecordCollection contains no more rows.')
def __getitem__(self, key):
""" 支持索引操作 并缓存已经取过的 记录 """
is_int = isinstance(key, int)
if is_int:
key = slice(key, key + 1)
while len(self) < key.stop or key.stop is None:
try:
next(self)
except StopIteration:
break
rows = self._all_rows[key]
if is_int:
return rows[0]
else:
return RecordCollection(iter(rows))
def __len__(self):
return len(self._all_rows)
def all(self, as_dict=False, as_ordereddict=False):
""" 返回所有Record列表 """
rows = list(self)
if as_dict:
return [r.as_dict() for r in rows]
return rows
def as_dict(self, ordered=False):
""" 返回字典列表 """
return self.all(as_dict=not(ordered), as_ordereddict=ordered)
def first(self, default=None, as_dict=False, as_ordereddict=False):
"""返回第一条记录, 返回default /或抛出default """
try:
record = self[0]
except IndexError:
if isexception(default):
raise default
return default
if as_dict:
return record.as_dict()
elif as_ordereddict:
return record.as_dict(ordered=True)
else:
return record
def one(self, default=None, as_dict=False, as_ordereddict=False):
"""返回唯一记录, 如果多个会抛出异常 """
try:
self[1]
except IndexError:
return self.first(default=default, as_dict=as_dict, as_ordereddict=as_ordereddict)
else:
raise ValueError('RecordCollection contained more than one row. '
'Expects only one row when using '
'RecordCollection.one')
|