前言
无意间发现了一个SS帐号分享站 ,但每次都需要手动获取帐号信息太麻烦了,这里用Python写一个爬虫来自动获取帐号信息。
分析
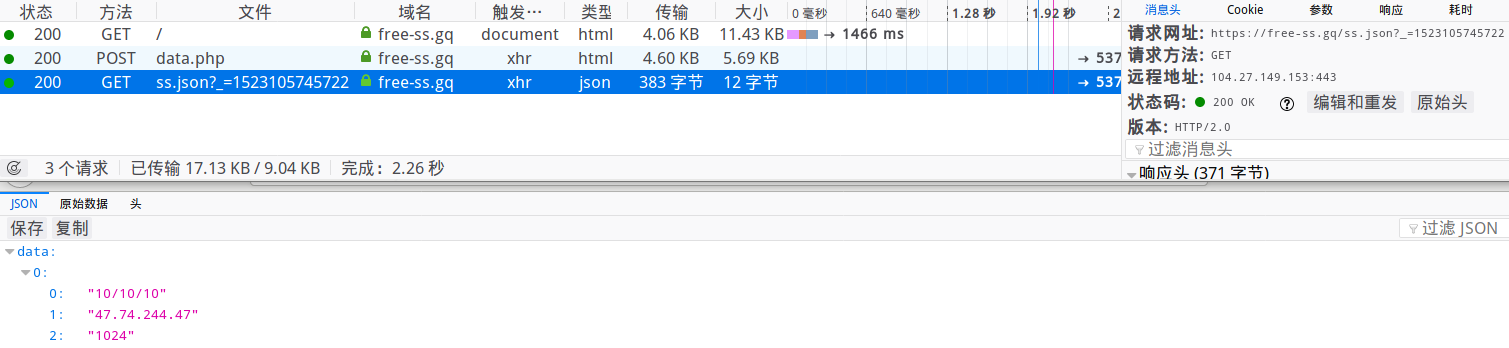
先来看一下网站源码。站长做了防爬处理,数据并不保存在源代码中,并且针对爬虫常见的模拟浏览器手段进行检测。
1 2 3 4 5 6 7 8 9 10 11 12 var a = '1a52316b1ed72c8f' ;var b = 'cd3e6a7914085b2f' ;var c = '327bd961633a77c4' ;var x = CryptoJS .enc .Latin1 .parse (a);var y = CryptoJS .enc .Latin1 .parse (b);$.post ("data.php" ,{a :a,b :b,c :c},function (data ){ var dec = CryptoJS .AES .decrypt (data,x,{iv :y,mode :CryptoJS .mode .ECB ,padding :CryptoJS .pad .Pkcs7 }); var tbdt = $.parseJSON (dec.toString (CryptoJS .enc .Utf8 )) }
可以看到流程如下
判断是否是正常的浏览器,如果正常,就用POST方法提交正确的a,b,c 参数,服务端会返回一串AES密文
用a,b分别初始化key,iv,用Crypto-js库去解密返回的数据
解密后,重新排版,优化显示
这里我们用Python去模拟整个过程
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 import reimport base64import requestsfrom Crypto.Cipher import AESheaders = {'User-Agent' :'Mozilla/5.0 (Windows NT 10.0; WOW64; rv:59.0) Gecko/20100101 Firefox/59.0' } url= "https://free-ss.site/" url2="https://free-ss.site/data.php" s = requests.session() html = s.get(url,headers=headers,timeout=3 ) a,b,c = re.findall(r"\'(.*?)\'" ,html.text)[6 :9 ] p_data = {'a' :a,'b' :b,'c' :c} msg = s.post(url2,headers=headers,data=p_data,timeout=3 ) endata = base64.b64decode(msg.text) key = bytes (a,encoding="utf-8" ) aes = AES.new(key,AES.MODE_ECB) data = aes.decrypt(endata).decode('utf-8' )
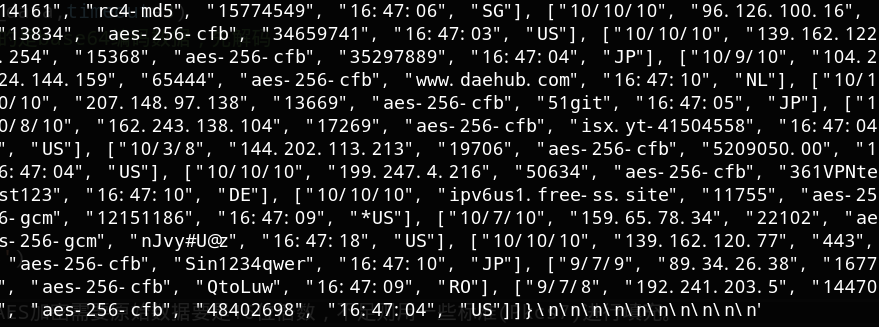
我们可以看到数据末尾多了一些无用字符,因为AES加密需要原始数据块是16位的倍数,不足则用按照某些标准(诸如源码中的Pkcs7)进行填充补位。
1 2 3 4 5 6 7 8 9 10 import jsonss_data = re.findall(r'{.*}' ,data)[0 ] ss_json = json.loads(ss_data)['data' ] for i in ss_json: ss = "{}:{}@{}:{}" .format (i[3 ],i[4 ],i[1 ],i[2 ]) ss_url = "ss://" + bytes .decode( base64.b64encode(bytes (ss,encoding="utf8" )) ) print (ss_url)
后来发现网站每次使用的加密方法都是随机的,Crypto-js一共实现了AES的5种加密模式:CBC、CFB、CTR、ECB、OFB,每种都用Python实现太麻烦了,这里我们取个巧:判断加密模式,如果是ECB,则进行解密,否则重新请求网页信息。整个Demo如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 import reimport base64import jsonimport requestsfrom Crypto.Cipher import AESif __name__ == '__main__' : headers = {'User-Agent' :'Mozilla/5.0 (Windows NT 10.0; WOW64; rv:59.0) Gecko/20100101 Firefox/59.0' } url= "https://free-ss.site/" url2="https://free-ss.site/data.php" while (1 ): s = requests.session() html = s.get(url,headers=headers,timeout=3 ) mode = re.findall(r"CryptoJS.mode.(\w{3})" ,html.text) print (mode) if 'ECB' in mode: a,b,c = re.findall(r"\'(.*?)\'" ,html.text)[6 :9 ] p_data = {'a' :a,'b' :b,'c' :c} msg = s.post(url2,headers=headers,data=p_data,timeout=3 ) endata = base64.b64decode(msg.text) key = bytes (a,encoding="utf-8" ) aes = AES.new(key,AES.MODE_ECB) data = aes.decrypt(endata).decode('utf-8' ) ss_data = re.findall(r'{.*}' ,data)[0 ] ss_json = json.loads(ss_data)['data' ] for i in ss_json: ss = "{}:{}@{}:{}" .format (i[3 ],i[4 ],i[1 ],i[2 ]) ss_url = "ss://" + bytes .decode( base64.b64encode(bytes (ss,encoding="utf8" )) ) print (ss_url) break
后续
完整脚本已经放在Github 上,一键版下载地址
本文仅供学习交流,如有冒犯之处,联系可删。
参考